
The study of 67,000 headlines examined how AI-related news headlines can fuel public fear and misunderstanding.

Despite the "troubled stand-up" stereotype, the study only found modest support for the idea that comedians have a unique profile of psychological dysfunction.

This asymmetry in seasonal temperature variability is due to the interplay of solar radiation, Earth's surface characteristics, and atmospheric dynamics, including the moderating influence of large bodies of water and the behavior of atmospheric currents like the jet stream.

The five-digit arrangement might offer a balance between dexterity and the energy needed for limb control, but it is also possible that it is simply an evolutionary rut difficult to escape, as gaining more digits may not provide significant advantages or might demand difficult genetic changes.

These tiny hairs alert us to the presence of bugs and changes in the air, help regulate body temperature, and provide some protection from scratches.

Biofortification is an agricultural process that increases the concentration of essential micronutrients in staple crops to address hidden hunger and malnutrition.
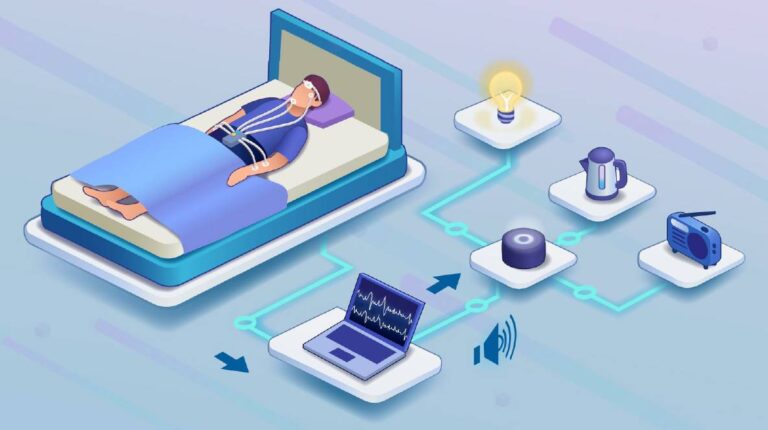
Scientists have shown it is possible to control smart home devices from within lucid dreams using muscle signals, opening up intriguing possibilities for dream-reality interaction.

Pink lemonade's origins are a blend of fact and folklore, with stories attributing its creation to circus vendors like Pete Conklin and Henry E. Allott in the 1850s. The drink's roots intertwine with European immigrant traditions, leading to various innovative twists in America.

Yes, humans are still evolving, though at a slower pace than in the past. Genetic changes, though subtle, continue to shape our species over generations.

Revolutionary advancements in science are reshaping our world, from the minuscule powerhouses within our cells to the vast complexities of space.

Gabriele Amorth was an exorcist in the Catholic Church who contributed to religious publishing, participated in the Italian Resistance during WWII, and performed numerous exorcisms.

Dale Chihuly is celebrated for his imaginative glass sculptures, but his foundational years in Tacoma, Washington, and his subsequent academic journey substantially shaped his artistic endeavors.

The Hanging Gardens of Babylon were possibly built by King Nebuchadnezzar II for his wife, Amytis, to mirror her lush homeland of Media.

The history of the QWERTY keyboard traces back to typewriters, designed to prevent jamming and help telegraph operators, becoming the standard layout we use today.

The process of determining the genetic sex of an individual through the interplay of chromosomes, genes, and developmental biology.
